1. 镜像
1.1 Docker为什么轻量级
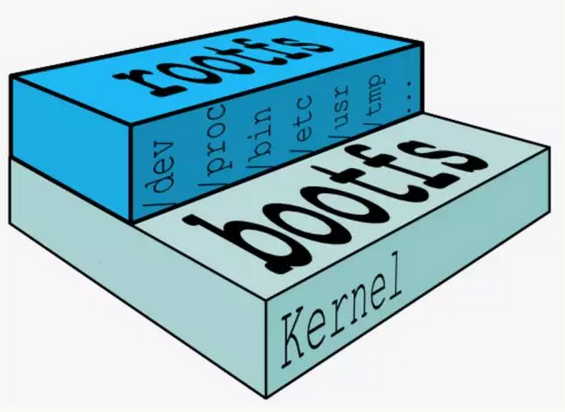
- Linux 操作系统由内核空间和用户空间组成
- 内核空间是 kernel,Linux 刚启动时会加载 bootfs 文件系统,之后 bootfs 会被卸载掉。
- 用户空间的文件系统是 rootfs,包含我们熟悉的 /dev, /proc, /bin 等目录。
对于 base 镜像来说,底层直接用 Host 的 kernel,自己只需要提供 rootfs 就行了。
- base 镜像只是在用户空间与发行版一致,kernel 版本与发型版是不同的。
- 容器只能使用 Host 的 kernel,并且不能修改。如果容器对 kernel 版本有要求(比如应用只能在某个 kernel 版本下运行),则不建议用容器,这种场景虚拟机可能更合适。
1.2 镜像的分层结构
可以看到,新镜像是从 base 镜像一层一层叠加生成的。每安装一个软件,就在现有镜像的基础上增加一层。
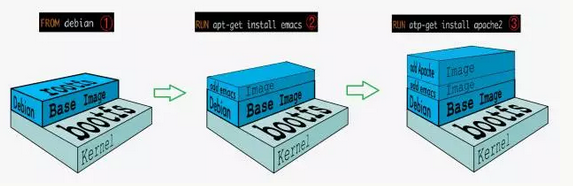
Docker 镜像采用分层结构最大的好处就是:共享资源。而且镜像的每一层都可以被共享。
1.3 可写的容器层
当容器启动时,一个新的可写层被加载到镜像的顶部。 这一层通常被称作“容器层”,“容器层”之下的都叫“镜像层”
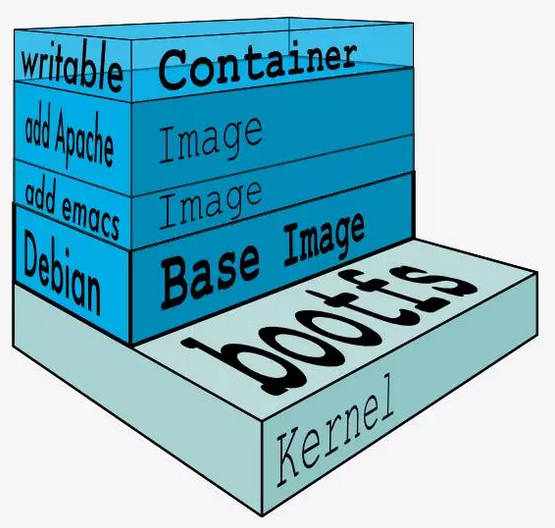
所有对容器的改动 - 无论添加、删除、还是修改文件都只会发生在容器层中。
-
添加文件 在容器中创建文件时,新文件被添加到容器层中。
-
读取文件 在容器中读取某个文件时,Docker 会从上往下依次在各镜像层中查找此文件。一旦找到,打开并读入内存。
-
修改文件 在容器中修改已存在的文件时,Docker 会从上往下依次在各镜像层中查找此文件。一旦找到,立即将其复制到容器层,然后修改之。
-
删除文件 在容器中删除文件时,Docker 也是从上往下依次在镜像层中查找此文件。找到后,会在容器层中记录下此删除操作。
容器层记录对镜像的修改,所有镜像层都是只读的,不会被容器修改,所以镜像可以被多个容器共享。
1.4 构建镜像
Docker 提供了两种方法构建镜像:
- docker commit 命令
- 这是一种手工创建镜像的方式,容易出错,效率低且可重复性弱
- 更重要的:使用者并不知道镜像是如何创建出来的,里面是否有恶意程序。也就是说无法对镜像进行审计,存在安全隐患。
-
Dockerfile 构建文件
-
运行命令格式
-
Shell 格式:
<instruction> <command>. 当指令执行时,shell 格式底层会调用/bin/sh -c <command>```python ENV name Cloud Man ENTRYPOINT ["/bin/sh", "-c", "echo Hello, $name"] ``` -
Exec 格式
<instruction> ["executable", "param1", "param2", ...]
-
-
RUN vs CMD vs ENTRYPOINT
-
RUN 执行命令并创建新的镜像层,RUN 经常用于安装软件包。
-
CMD 设置容器启动后默认执行的命令及其参数,但 CMD 能够被 docker run 后面跟的命令行参数替换。
- Exec 格式:CMD [“executable”,”param1”,”param2”] 这是 CMD 的推荐格式。
- CMD [“param1”,”param2”] 为 ENTRYPOINT 提供额外的参数,此时 ENTRYPOINT 必须使用 Exec 格式。
- Shell 格式:CMD command param1 param2
-
ENTRYPOINT 配置容器启动时运行的命令。一定会被执行,即使运行 docker run 时指定了其他命令。
-
-
镜像名字组成
[registry-host]:[port]/[username]/xxx:tag
2. 容器
cgroup 和 namespace 是最重要的两种技术。cgroup 实现资源限额, namespace 实现资源隔离。
2.1 Control Group。
Linux 操作系统通过 cgroup 可以设置进程使用 CPU、内存 和 IO 资源的限额。

- /sys/fs/cgroup/cpu/docker
- /sys/fs/cgroup/memory/docker
- /sys/fs/cgroup/blkio/docker
2.2 namespace
在每个容器中,我们都可以看到文件系统,网卡等资源,这些资源看上去是容器自己的。 Linux 实现这种方式的技术是 namespace。namespace 管理着 host 中全局唯一的资源,并可以让每个容器都觉得只有自己在使用它。换句话说,namespace 实现了容器间资源的隔离。
- Mount namespace 让容器看上去拥有整个文件系统
- UTS namespce 让容器有自己的 hostname
- IPC namespace 让容器拥有自己的共享内存和信号量(semaphore)来实现进程间通信,而不会与 host 和其他容器的 IPC 混在一起。
- PID namespace
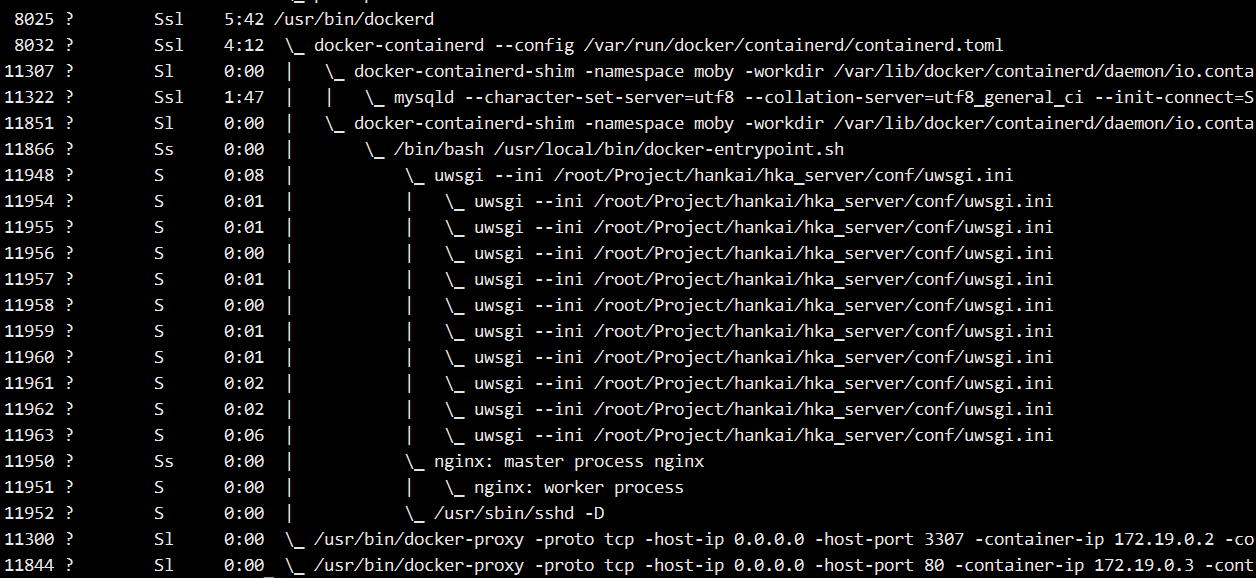
容器在 host 中以进程的形式运行。例如当前 host 中运行了两个容器:
 通过 ps axf 可以查看容器进程:
通过 ps axf 可以查看容器进程:
 如果我们进入到某个容器,ps 就只能看到自己的进程了:
如果我们进入到某个容器,ps 就只能看到自己的进程了:
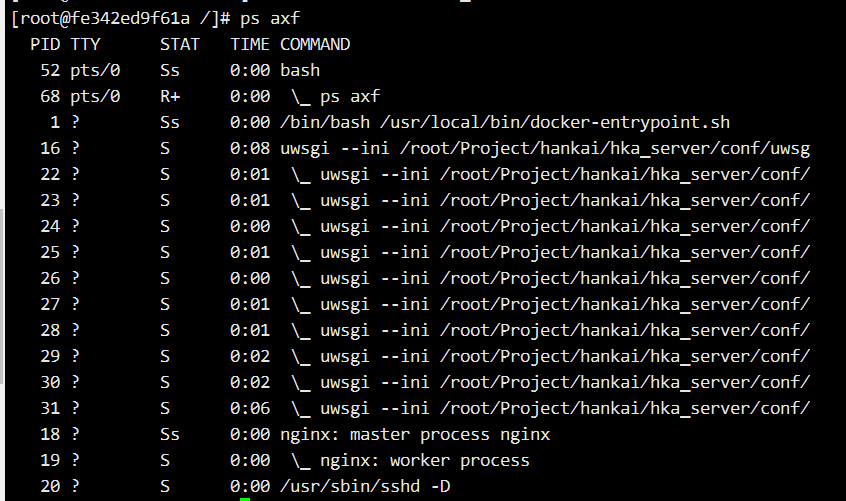 容器中进程的 PID 不同于 host 中对应进程的 PID,容器中 PID=1 的进程当然也不是 host 的 init 进程。也就是说:容器拥有自己独立的一套 PID,这就是 PID namespace 提供的功能。
容器中进程的 PID 不同于 host 中对应进程的 PID,容器中 PID=1 的进程当然也不是 host 的 init 进程。也就是说:容器拥有自己独立的一套 PID,这就是 PID namespace 提供的功能。 - Network namespace 让容器拥有自己独立的网卡、IP、路由等资源
- User namespace 让容器能够管理自己的用户,host 不能看到容器中创建的用户。
3. 网络
Docker 安装时会自动在 host 上创建三个网络,我们可用 docker network ls 命令查看:
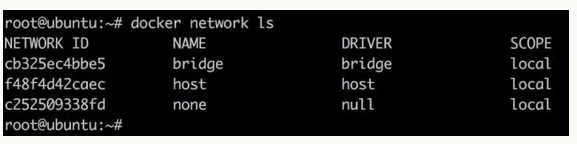
- none: 网络就是什么都没有的网络.
- 封闭意味着隔离,一些对安全性要求高并且不需要联网的应用可以使用 none 网络。
- 比如某个容器的唯一用途是生成随机密码,就可以放到 none 网络中避免密码被窃取。
- host: 容器共享 Docker host 的网络栈,容器的网络配置与 host 完全一样。
- 直接使用 Docker host 的网络最大的好处就是性能
- 不便之处就是牺牲一些灵活性,比如要考虑端口冲突问题
- 另一个用途是让容器可以直接配置 host 网路.
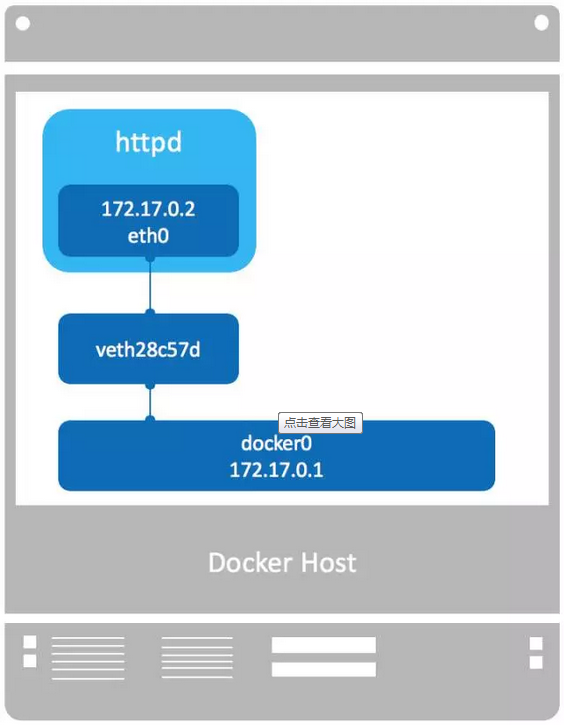
3. bridge 网络
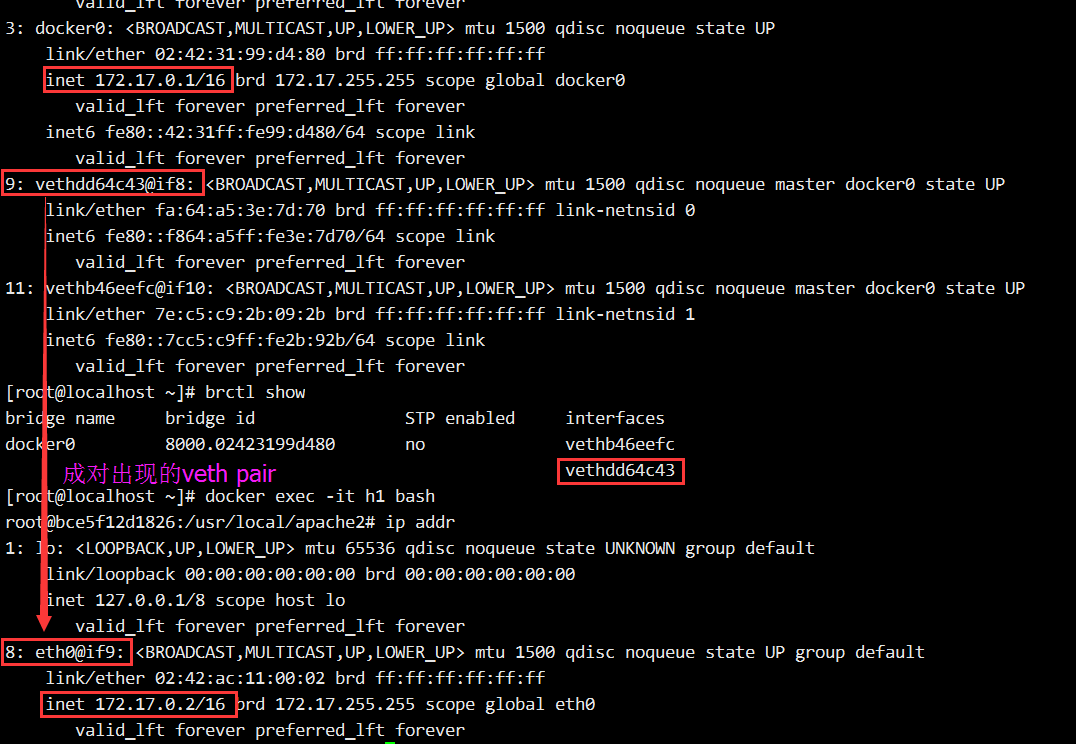
Docker 安装时会创建一个 命名为 docker0 的 linux bridge。如果不指定–network,创建的容器默认都会挂到 docker0 上
3.1 创建bridge
docker network create --driver bridge --subnet 172.22.16.0/24 --gateway 172.22.16.1 my_net2
-
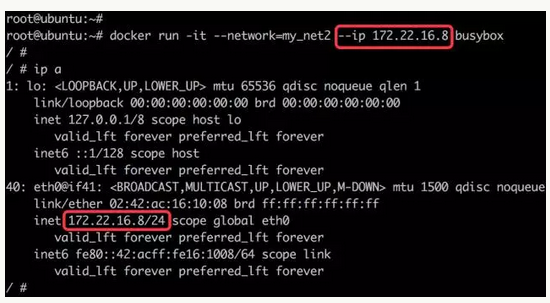
创建容器,并指定bridge 到目前为止,容器的 IP 都是 docker 自动从 subnet 中分配,我们能否指定一个静态 IP 呢?只有使用 –subnet 创建的网络才能指定静态 IP。
-
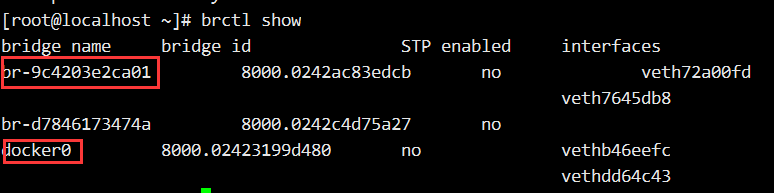
不同bridge间是不能通信的

-
给docker0上的某个容器加上一张网卡,使之能与my_net2中容器通信
docker network connect my_net2 h1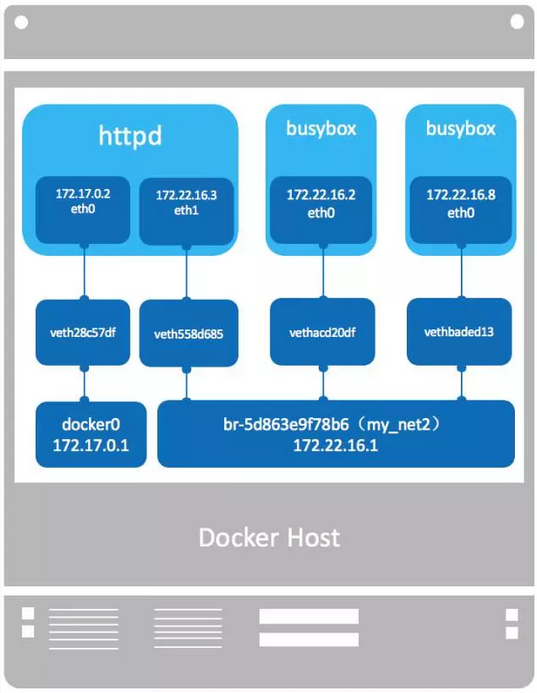
3.2 容器间通信
- ip 通信
两个容器要能通信,必须要属于同一个网络的网卡。具体做法是
- 在容器创建时通过 –network 指定相应的网络,
- 或者通过 docker network connect 将现有容器加入到指定网络。
- Docker DNS server通信
通过 IP 访问容器虽然满足了通信的需求,但还是不够灵活。因为我们在部署应用之前可能无法确定 IP,部署之后再指定要访问的 IP 会比较麻烦。
- 使容器可以直接通过“容器名”通信。只要在启动时用 –name 为容器命名就可以了。
- 使用 docker DNS 有个限制:只能在 user-defined 网络中使用
-
joined容器 它可以使两个或多个容器共享一个网络栈,共享网卡和配置信息,joined 容器之间可以通过 127.0.0.1 直接通信。
docker run -d -it --name=web1 httpddocker run -it --network=container:web1 busybox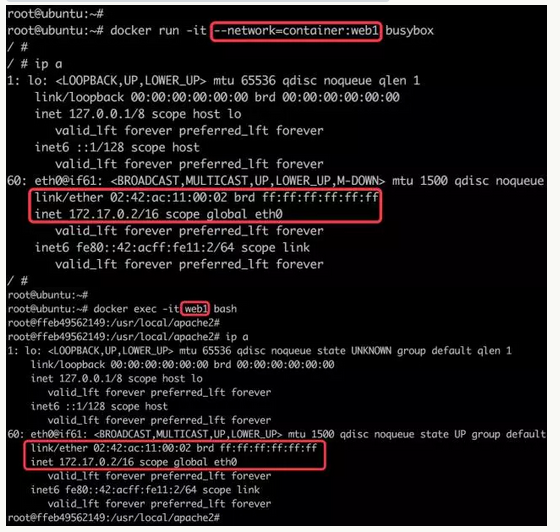
- 不同容器中的程序希望通过 loopback 高效快速地通信,比如 web server 与 app server。joined 容器非常适合以下场景:
- 希望监控其他容器的网络流量,比如运行在独立容器中的网络监控程序。
3.3 容器与外界的连接
-
容器访问外网
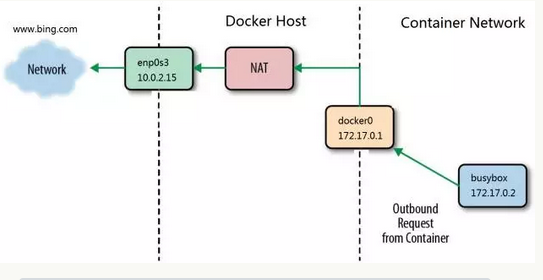
-
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE其含义是:如果网桥 docker0 收到来自 172.17.0.0/16 网段的外出包,把它交给 MASQUERADE 处理。而 MASQUERADE 的处理方式是将包的源地址替换成 host 的地址发送出去,即做了一次网络地址转换(NAT)。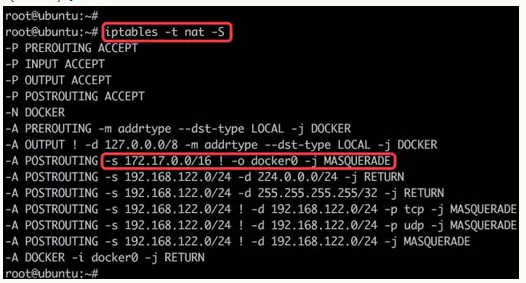
-
docker0 的网络包:
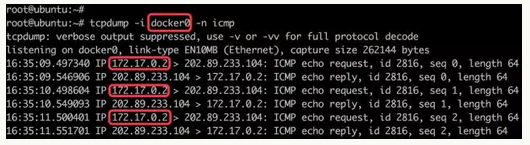
-
host机器网卡网络包:
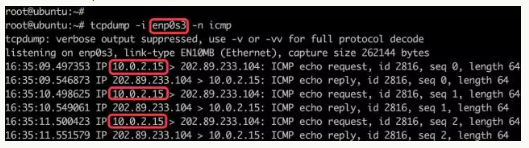
-
-
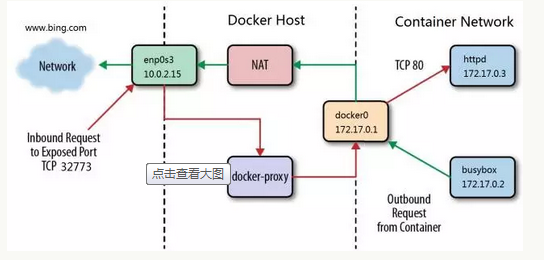
外网访问容器
-
每一个映射的端口,host 都会启动一个 docker-proxy 进程来处理访问容器的流量:

- docker-proxy 监听 host 的 32773 端口。
- 当 curl 访问 10.0.2.15:32773 时,docker-proxy 转发给容器 172.17.0.2:80。
- httpd 容器响应请求并返回结果
-
4.存储
Docker 为容器提供了两种存放数据的资源:
- 由 storage driver 管理的镜像层和容器层。
- 正是 storage driver 实现了多层数据的堆叠并为用户提供一个单一的合并之后的统一视图。
- 某些无状态的应用(busybox是个工具箱)没有持久化的数据,直接将数据放在由 storage driver 维护的层中是很好的选择
- Data Volume。
Data Volume 本质上是 Docker Host 文件系统中的目录或文件,能够直接被 mount 到容器的文件系统中
- Data Volume 是目录或文件,而非没有格式化的磁盘(块设备)。
- 容器可以读写 volume 中的数据。
- volume 数据可以被永久的保存,即使使用它的容器已经销毁。
4.1 两种类型的volume
-
bind mount bind mount 是将 host 上已存在的目录或文件 mount 到容器。
- 使用单一文件有一点要注意:host 中的源文件必须要存在,不然会当作一个新目录 bind mount 给容器。
-
docker managed volume
docker run -d - p 80:80 -v /usr/local/apache2/htdocs httpd- 容器启动时,简单的告诉 docker “我需要一个 volume 存放数据,帮我 mount 到目录 /abc”。
- docker 在 /var/lib/docker/volumes 中生成一个随机目录作为 mount 源。
- 如果 /abc 已经存在,则将数据复制到 mount 源,
- 将 volume mount 到 /abc.此时的/abc已经不再由storage driver 管理了。他是一个data valume
- docker managed volume支持支目录
4.2 数据共享
-
容器与host共享数据 用data volume来共享数据.
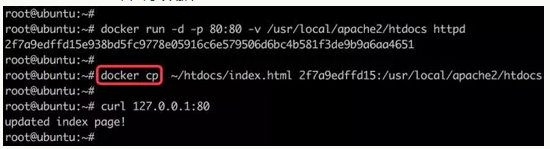
当然我们也可以直接通过 Linux 的 cp 命令复制到 /var/lib/docker/volumes/xxx。
-
容器间共享数据 同一个host的volume, mount到多个容器